


Introduction
I want to take a look at a very basic Ollama Artificial Intelligence (AI) model and track the information flow from query to results. For those who are new to AI, Ollama is a Application Program Interface (API) for Large Language modes (LLM). The combination of API and LLM make up a basic AI. And I want to examine how data flows in this process.
The basic components of the model include the User, some type of interface between the User and the Ollama, The Ollama API itself, and a LLM. It should be noted that there are many different LLM models. As this model does not call out a specific LLM, the limiting factor will be if the LLM will run on the hardware being used. The larger the LLM model, the more precise the response, however more resources, in the form of processor cores and RAM, will be required to run it.
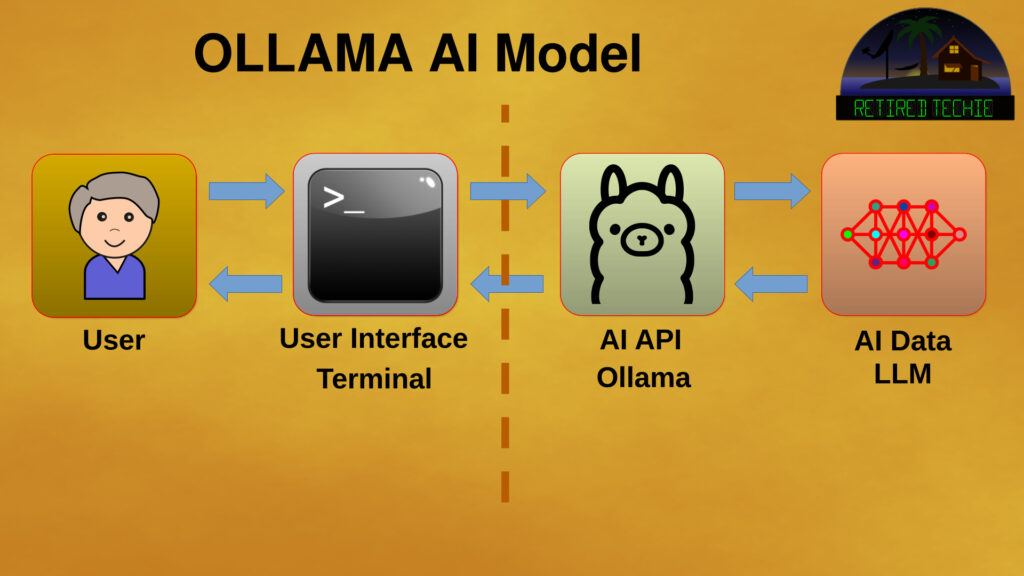
The User
The starting point for informational flow is the User. Users provide input in the form of a query. These queries are entered into a Human Interface (HI) connected to the AI model, usually through an Operating System (OS) that the AI is running on. At a very basic level this can be as simple as text. However, depending on the interface type it could also include more advanced input in the form of Multimedia.
The Interface
An interface is part of an OS. In this model, at a very basic level, this can be as simple as a terminal. Or it could be something more complex, like a web page. While an OS has many functions, in our model it has two primary functions; to route a user query to the AI model, and provide the basic resources to allow the AI model to function.
Ollama
Ollama is the API for the AI model, interacting with the LLM on behalf of the user. User queries are forwarded by the interface to Ollama, which in turn works with the LLM to analyze and formulate a response. Once a response has been determined, Ollama forwards it back through the interface to the user.
Beyond user queries, Ollama also manages the LLM. This includes pulling (downloading), storing, removing, and allowing the user to select which LLM is used.
Large Language Model
An LLM is the brain of the AI model. The LLM consists of large quantities of data that has been indexed, tokenized, layered, and transformed to analyze ha human query, research the query, and generate a human readable response to the query. The process of organizing the data within a LLM is referred to as training.
Most downloadable LLM models are either created, or based on models created by Tech Companies. For example Gemma ultimately comes from Google and llama ultimately comes from Meta (Facebook parent company).
Running a particular AI will be dependent on if the Hardware can run the LLM. And this depends on the number of parameters and the level of quantization.
Conclusion
Ollama has allowed running local AI models on most modern computers (less than five years old). While Ollama itself is not hardware intensive, the LLM you run will have minimum requirements. The hardware requirements for any specific LLM will depend on its parameters (size), and quantization (compression).
While not covered in this article, it is possible to customize their responses to your situation, with your own documentation using a process know as Retrieval Augmented Generation or RAG.
Using Ollama it has become practical to run AI models on local hardware. However, as good as these models are, they will still fall short of the online AI models. Their advantage over the online AI, you are not tracked by the Tech companies, and they are available when the Internet is down.
Leave a Reply